
On Observability
...and the unacceptable asymmetry between science and sports

The Almost Perfect Game
On June 2, 2010, Armando Galarraga took the mound for the Detroit Tigers. At 28, the Venezuelan pitcher was fighting to stay relevant after coming off a rough season. Nearly three hours later, at the top of the ninth, he stood one out away from a perfect game.
Galarraga threw. The batter hit a slow ground ball, easily picked up and thrown to first. Galarraga ran to first, felt his foot hit the base, felt the ball hit his glove, then felt the batter run by. He knew he had done it. A perfect, life-changing game.
An instant later, he turned towards the umpire, Jim Joyce, to see two outstretched arms. Safe.
The stadium fell silent.
Seconds later, broadcasts around the country showed the footage, from every angle, that made clear what Galarraga knew intuitively: the call was wrong.



In 2010, Major League Baseball had no mechanism to overturn the call on the field. The umpire’s call was law. After Joyce saw the replay himself, he publicly apologized, in tears, “I just cost that kid a perfect game.”

The call stood, but baseball didn’t. A few years later, MLB expanded instant replay to allow plays like this to be overturned.
Moneyball 2.0
Baseball is famous for observability, personified by Brad Pitt’s portrayal of Billy Beane in Michael Lewis’ Moneyball. For the first time, players and teams had statistics on what worked, not just what looked good. In the years since Billy Beane changed the game, baseball (and every other sport) has only become more quantified.
In 2013, Justin Turner was released by the New York Mets. At 29, he was a utility infielder with no single moment of failure, just years of never being quite good enough.
When Turner landed with the Dodgers, the coaches showed him slow-motion replays overlaid with new data that was coming to the sport: exit velocity, launch angle, ball flight. Turner could now see, in frame after painful frame, that he was hitting the top of the ball. Over and over.
He adjusted his stance and lowered his bat imperceptibly.
The next season, home runs replaced fly outs. A bench player became an All-Star and a franchise cornerstone. Nothing about baseball changed. Nothing about Turner’s body changed. The only thing that changed was that his failures became legible while there was still time to learn from them.



The Cost of Invisibility
For many people with advanced cancer, treatment is not a one-time decision. It’s a sequence of desperate attempts. The gold standard therapy works for a while, then stops. Another takes its place. Then another. The only hope for these patients ultimately becomes experimental new drugs entering clinical trials.1
Multiple myeloma is one such unforgiving disease. The blood cancer gradually undermines the immune system and while treatments can hold it back for a time, resistance is common. When a new therapy shows any efficacy after all other options have run out, it isn’t incremental, it’s a lifeline.
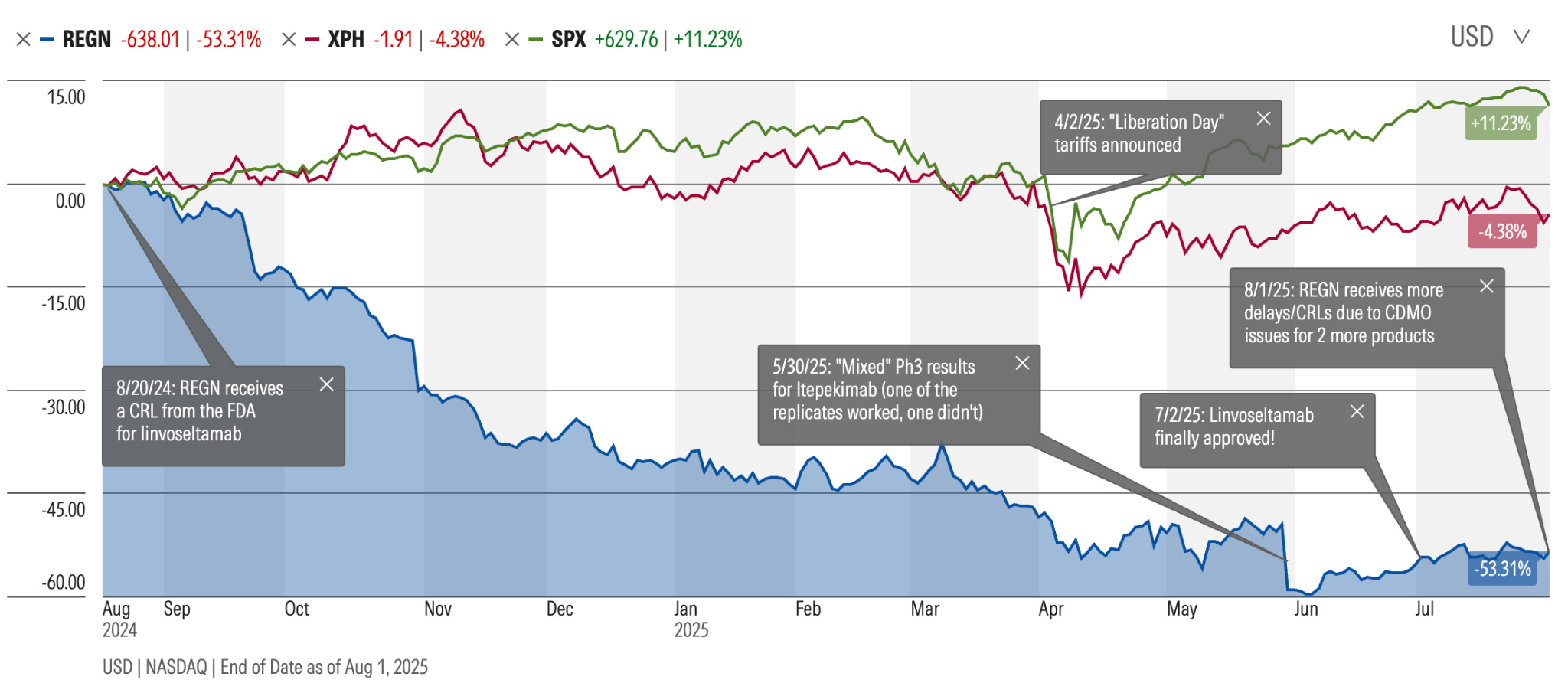
In early 2024, Regeneron seemed to be sitting on one such lifeline. Linvoseltamab, a bispecific antibody for multiple myeloma, was showing progress. Even among this hard-to-treat population, the drug seemed to be helping 70% of patients, and many were achieving complete or near-complete remission. The drug had just earned a Priority Review designation from the FDA and August 22 was the expected deadline for approval.
For Regeneron, it was further proof that the company had become an R&D powerhouse. The company was riding high with a market cap just above $130 billion. For linvoseltamab, success felt inevitable and executives were no longer talking about if, only when: manufacturing ramp plans, launch sequencing, what this blockbuster would unlock next.
As with any upcoming launch, there were a few yellow lights on the project management spreadsheets, but nothing out of the ordinary. Earlier in the year, the FDA had flagged some manufacturing concerns during a routine pre-approval inspection at a third-party fill-finish site (the sites responsible for final packaging of the drug). There were no concerns about safety or efficacy, and Regeneron characterized the issues as procedural and addressable. Analysts treated it as routine. The anticipated approval date remained unchanged.
But on August 20, two days before waiting patients were hoping to hear good news, instead of an approval letter, Regeneron received a Complete Response Letter (a big fat no), halting approval for linvoseltamab until a successful re-inspection of the aforementioned third party manufacturing site. In the year that followed, similar inspection-related delays of manufacturing partners surfaced again and again, affecting other high-profile programs, including extended-dose formulations of Regeneron’s blockbuster eye drug and additional oncology assets. Around the same time, a pair of large, nominally identical Phase III trials in COPD delivered sharply divergent results (one meeting its endpoint, the other missing it entirely). What had looked like a one-off routine manufacturing delay started feeling like something much bigger. Did Regeneron really know what was going on with its programs and partners?
A year later (compounded by other factors, including market pressure on its lead asset), Regeneron’s market cap had fallen by about $70 billion, down over 50% from its peak during a time when the S&P and broader pharma industry was relatively stable. Scientists who had spent years focusing on proving a biological mechanism were suddenly being asked to explain clinical and manufacturing issues over which they had no real visibility or oversight.
Regeneron isn’t an outlier. Similar issues have publicly plagued Lilly, AbbVie, Merck, and others. One top 10 pharma leader once told me that tech transfer issues to CDMOs (contract development and manufacturing organization) is, from their vantage point, the single biggest cause of drug launch delays. Not the science. Tech transfer!
One successful pharma CEO shared a particularly vivid story with me last year. When a CDMO’s yields came in 30% lower than anticipated, they flew “a hundred people” (I still don’t know if this was hyperbole or not!) to the facility to investigate. The ultimate culprit was a single underspecified execution detail: the seed culture was settling and wasn’t being fully resuspended before it entered the fermentation tank. A trivial inversion to mix the contents of a tube solved the problem. But at what cost?
As an industry, we tend to blame “the science” when things go wrong, but far too often, we’re failing or falling behind not because of the inherent complexity of biology, but because of botched handoffs or lack of visibility into partners and processes on which we’re dependent. These issues cost far more than time. A one year delay on a blockbuster drug costs billions of dollars (lost sales, shortened patent window, wasted runs, distraction from the pipeline, etc.) and countless lives.
And there’s a quieter long-term cost that compounds the others. Fields like manufacturing, aviation, and robotics are generating rich records of how work is actually performed, which serve as fuel for advancements in physical AI and automation. Science is not. Without observability, we won’t benefit as much from advances in AI and automation later, not because the machines aren’t capable, but because we never gave them anything real to learn from.23
Beyond Moneyball
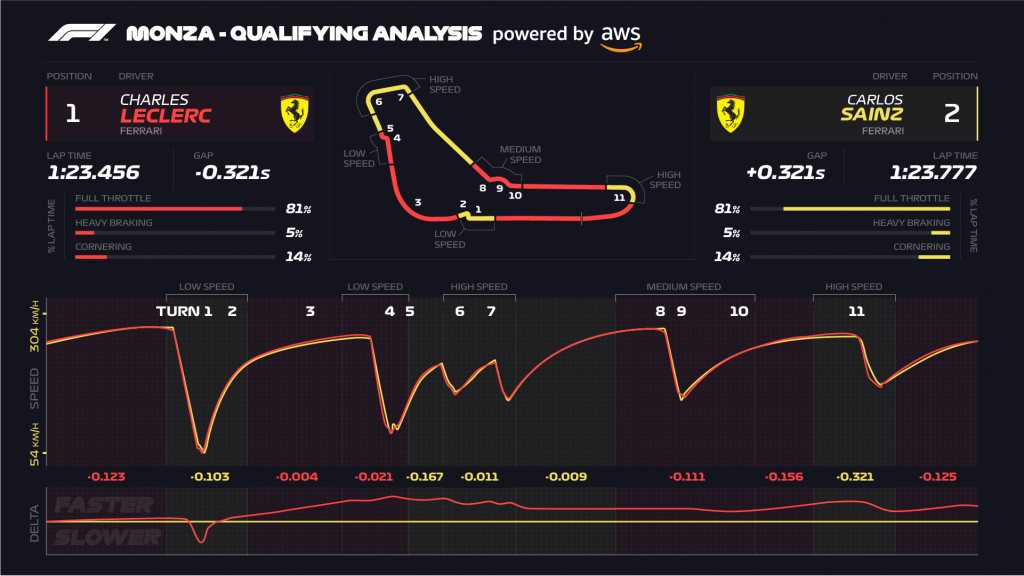
While baseball became famous for its statistics, most elite domains long ago accepted that performance depends on making failure observable, legible, and openly discussable. Athletes watch film. Pilots run post-incident reviews. Formula 1 teams analyze telemetry lap by lap to understand exactly where speed was lost.4 Nuclear power operators document and share near-misses in obsessive detail, treating silence as the greatest of all risks. Most fields assume that learning requires seeing, not just outcomes, but causes.
Science, strangely, does not.
When an experiment fails, the scientist doesn’t get to look at a replay. If there’s any post-mortem at all, it’s nearly impossible to build a shared reconstruction of what actually happened. Sometimes a shrug that biology is hard, sometimes hours of mind-numbing meetings about what could have happened. Months of work collapse into a null result. Worse, our inability to accurately identify the cause of failure means we often misattribute it, wrongly nullifying a hypothesis and missing a life-saving opportunity, rather than correcting a confounding variable (an environmental factor, an expired reagent, a flick of the wrist).
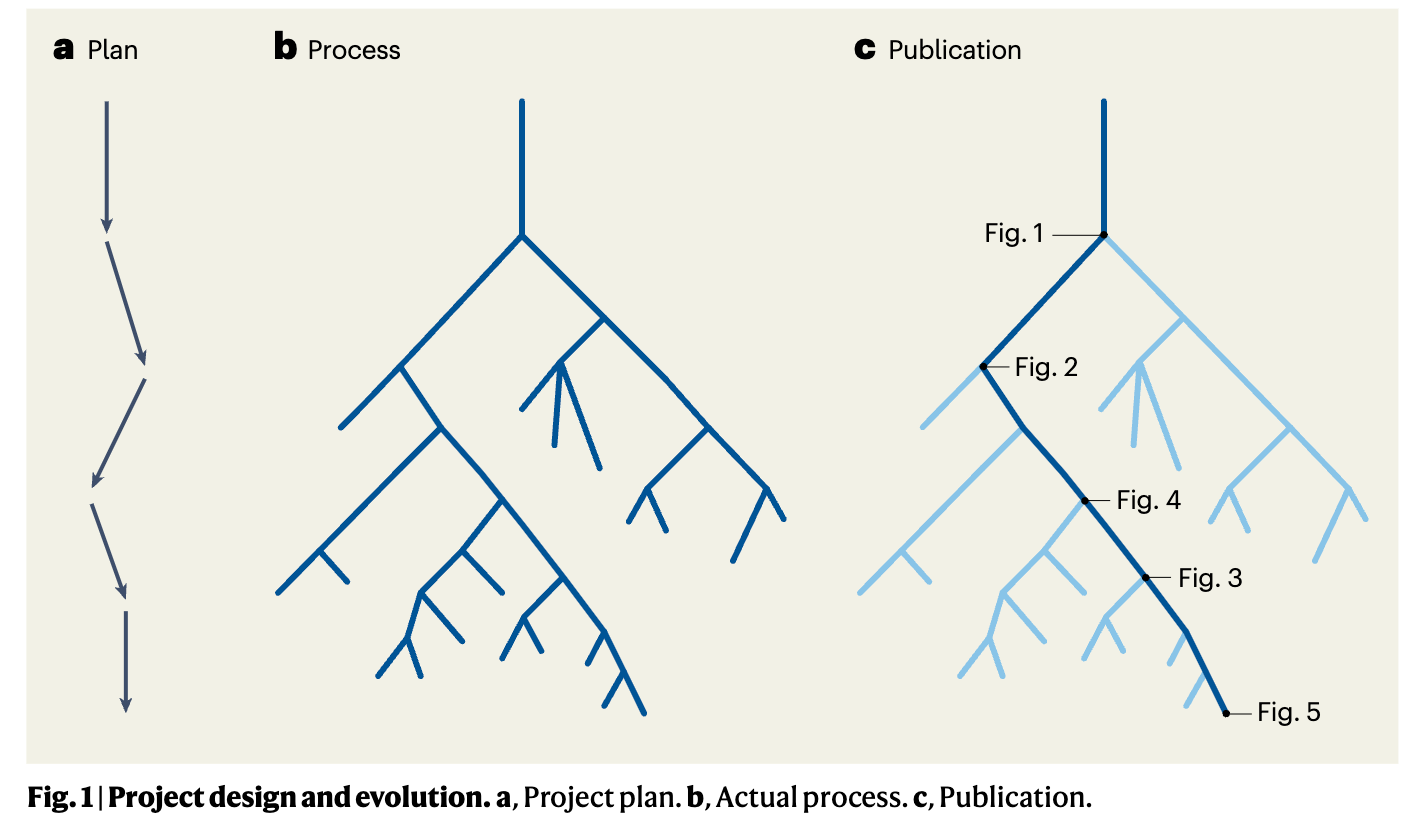
When science does succeed, it leaves behind an extraordinarily polished, sanitized artifact. Years of work compressed onto a few pages in Nature. A paper records the final figures, the winning experiment, the protocol that ultimately worked. It presents a coherent narrative that moves efficiently from hypothesis to result, trimmed of detours and uncertainty. It’s (typically) not deception, it’s compression. But it’s extremely lossy compression. Journals are not designed to capture the lived process of discovery, they’re designed to communicate outcomes.
It is difficult to defend a world in which a fumbled ground ball can be reconstructed from every angle within seconds, while a failed experiment that took months of work, millions (or billions!) of dollars, and is standing in the way of a cancer patient receiving a cure is left to speculation and memory. It’s difficult to defend a collegiate athletic department spending millions (!!) of dollars on software that creates practice films for their athletes but academic labs have no real tools to observe and help young scientists learn from their experiments. Where athletes get film rooms, scientists get shrugs and guesses.
Irreducibly Complex, Practically Blind
It’s tempting to treat this as simply a cultural problem. Scientists aren’t incentivized to publish failures, journals reward cleanliness, “publish or perish” academic systems mean we look for quick wins over meaning, reproducibility failures often provoke questions of fraud. We have our cultural issues but also deserve some grace.
It’s more often a lack of awareness than intentional omission.
Science is genuinely hard to observe. Experiments unfold slowly. Feedback is delayed by days, weeks, sometimes years. Water looks the same to a camera as hydrochloric acid. Science itself often carries some amount of irreducible complexity with noisy outcomes often indistinguishable from chance. Instrumentation can perturb the system being studied. When an experiment doesn’t work, there are often dozens of plausible explanations: a degraded reagent, a subtle environmental shift, an unnoticed procedural deviation, a mistaken assumption made early and carried forward. Without visibility into the process as it unfolded, these explanations collapse into speculation.
This is not because scientists lack rigor. It’s because science has never built the equivalent of a post-game film room, where scientists, like elite athletes, can “play back the tape” and see what went wrong, what could’ve been optimized, think about what to do next. A place where PIs and postdocs (the managers and coaches of science), have the tools to help young scientists learn from their small failures and build the taste to know what good looks like as early as possible.
Until we embrace this, we’ll continue to keep some of our highest potential players on the bench, unable to make the small adjustments that could help them be great. We’ll continue to ignore the most valuable learning opportunities that emerge on a daily basis. This is not an argument that with current tools, we can perfectly observe science, rather that we’ve been ignoring the low hanging fruit that’s already available if we deploy what has become standard in so many other fields.
The Fickle Promise of Autonomous Science
Against the backdrop of human limitations paired with the urgent need for science to tackle planetary scale problems, it’s not surprising that interest in autonomous science has exploded. The idea that machines might design, run, and interpret experiments faster than humans is deeply appealing. In its most optimistic form, autonomous science promises to compress decades of discovery into years, and years into months.
But most visions of autonomous science appear to assume that the hardest part of science is reasoning over existing knowledge — reading papers, generating hypotheses, selecting the next experiment — or generating more flexible robotic arms.5 In this framing, the scientific literature becomes the training set, and intelligence lives primarily in abstraction.
This is the wrong lesson.
I’m an enormous fan of autonomy. Despite not living in a city with Waymo, I’m one of their top riders. There’s no novelty factor for me anymore, it’s simply a better experience — truly superhuman driving.6
When autonomous driving began to look plausible, it wasn’t because we finally had good enough maps or clever enough models. What had been missing was any serious understanding of how driving actually worked in the wild.
Progress came only once we started watching. Cars were instrumented with vision, lidar, and GPS to understand the surrounding environment as it appeared moment by moment as they were driven around: cluttered, dynamic, ambiguous. The models learned how humans navigated that chaotic environment, how drivers anticipated risk, corrected small errors, negotiated uncertainty, and recovered when things went wrong. None of that lived in manuals or maps, only in practice
That work didn’t begin because it was obviously profitable. Much of the early, unglamorous foundation was laid through DARPA’s Grand Challenge for autonomous vehicles, which funded years of sensing, experimentation, and public failure long before autonomous driving made economic sense.7 Observability had to come first. Autonomy followed later.
And even then, autonomy in driving faced an unusually high bar. A self-driving car doesn’t get to be mostly right. It has to be superhuman to be accepted, robust across rare edge cases. The cost of failure is immediate and catastrophic and the model is always easy to blame.8
In that context, observability was largely a means to an end. Recording how humans drove mattered because it enabled full autonomy. There was limited value in giving average drivers detailed feedback on their own driving; most people have no interest in reviewing hours of telemetry or video on their driving, even if it would make them safer on the road. Driver’s ed is a means to a license we grudgingly accept, not an enjoyable elective.
Sports is the opposite: there is limited value in autonomy (we enjoy the game because of human imperfections), but enormous value in observability for its role in improving human performance.
Science is yet a third breed. There is enormous value in both observability and autonomy.
True autonomy in science faces a similarly high bar to self driving cars: an autonomous system that gets an experiment 80% right is 0% useful on its own. A robot that misplaces one reagent, mis-judges one timing decision, or shakes instead of stirs doesn’t get partial credit. In that sense, full autonomy in science is no easier than autonomy in driving. But unlike driving, science doesn’t need autonomy to reap enormous value from observability and we can reap the benefits of partial autonomy all along the way.

Giving scientists better visibility into how their experiments unfold today can improve performance, reproducibility, and transferability, driving accelerated progress even when humans remain firmly in the loop. Observability in science is not just a prerequisite for autonomy; it’s a tool for learning, for teaching taste, for preserving craft, and minimizing institutional knowledge loss.
Driving demanded perfection before observability could matter. Science can benefit long before that.
Instant Replay for Science
When an experiment fails, scientists don’t shrug and move on.
We stop. We stare at the data longer than we want to admit. We replay the protocol in our heads, step by step, trying to remember whether anything felt off. We ask a labmate. Then another. Maybe we bring it to a group meeting. The lab head squints at the plots. Hypotheses proliferate: maybe the reagent was old, maybe the incubation was too long, maybe the assay is finicky, maybe the biology is just messy today. Maybe we should re-do it. Maybe we should just move on. Hours are wasted, maybe days.
What’s missing in all of this effort isn’t intelligence, diligence, or care… it’s visibility and a clear understanding of the strike zone. There’s no replay, no film room for science.
Now, imagine being able to rewind. To be able to see the sequence of steps, how long each one took, and where the execution drifted slightly from the protocol or from what you usually did. To know when a reagent was prepared and whether it was fresh or expired, which plate was flipped, which row was skipped or duplicated, how the cell suspension was actually agitated.
Biology is mysterious, but most experimental failures do not have to be mysteries. With observability, those failures collapse from hours of speculation into seconds of clarity: what can be salvaged, what needs to be rerun, why. Time is saved, cognitive load collapses, and collective performance improves.
This kind of visibility doesn’t tell scientists what to think. It doesn’t replace intuition or flatten creativity. It doesn’t highlight incompetence, it makes expertise and opportunity visible. This is what people mean when they talk about “taste” in science: not a vibe or an aesthetic, but the practiced ability to navigate uncertainty without a map. Observability doesn’t replace that judgment, it makes it legible and transferable, so it doesn’t vanish when a senior postdoc leaves, when a startup fails, or after a layoff.
Science will always be hard. But here, perfection is the enemy of progress. We don’t need perfect visibility to benefit greatly from observability; we need enough to reduce ambiguity, save time, and let scientists stay in forward motion. A film room for science would not make discovery automatic. But it would make it robust, and far less lonely.
N.B: If you’ve gotten this far, it's possible that I’ve ruined both sports and science for you - sorry. Every time I watch a football game now, I start yelling at the screen ("omg! how is it that we have 6 cameras pointed at that one guy and yet there's NOTHING in science?").
If you too are realizing how criminally underserved the scientific community has been and now you want to help your elite scientists and your Billy Beanes get their equivalent of a film room for science, come talk to us at Transfyr. We’re still in stealth and are heads-down building, but we’re always happy to talk with scientists, operators, and leaders who feel this pain acutely. We're already helping our partners level up faster, build institutional knowledge, and drive towards automation.
My email is annamarie [at] transfyr.ai
Oh, and we’re hiring software, AI, and perception engineers! If you want to work on frontier physical AI in the most important domain in the planet, please apply to join us! https://transfyr.ai/#join-usMany thanks Christina, Daniel, Renee, Ari, Kathryn, John, Mike, and Rob for helpful comments on an earlier version of this! And thanks to my mom for being my North Star around the legibility of this piece for a non-technical audience (and always being my Editor in Chief!).
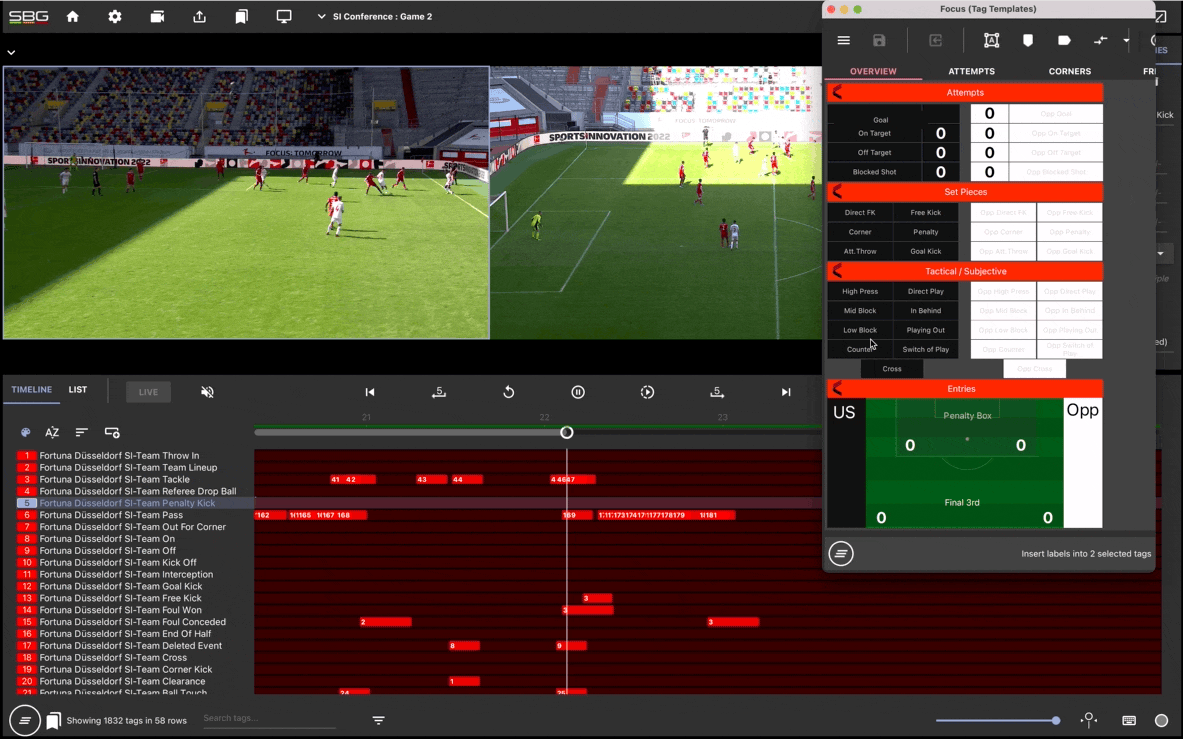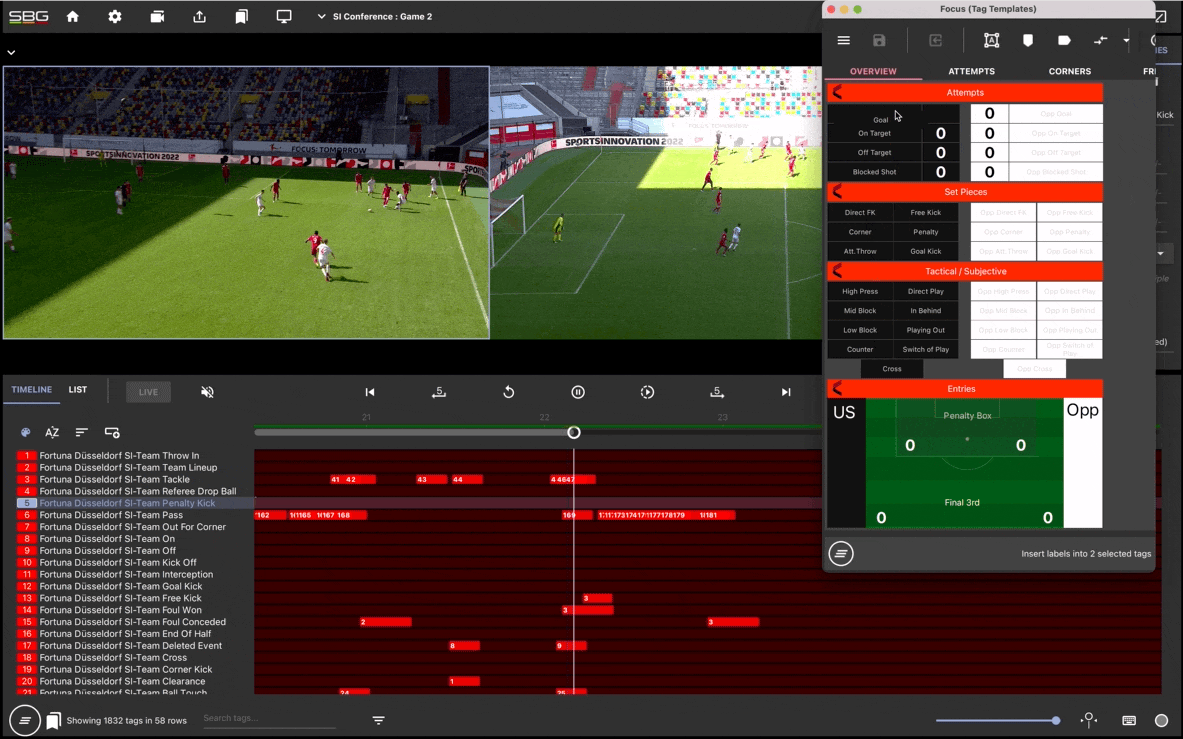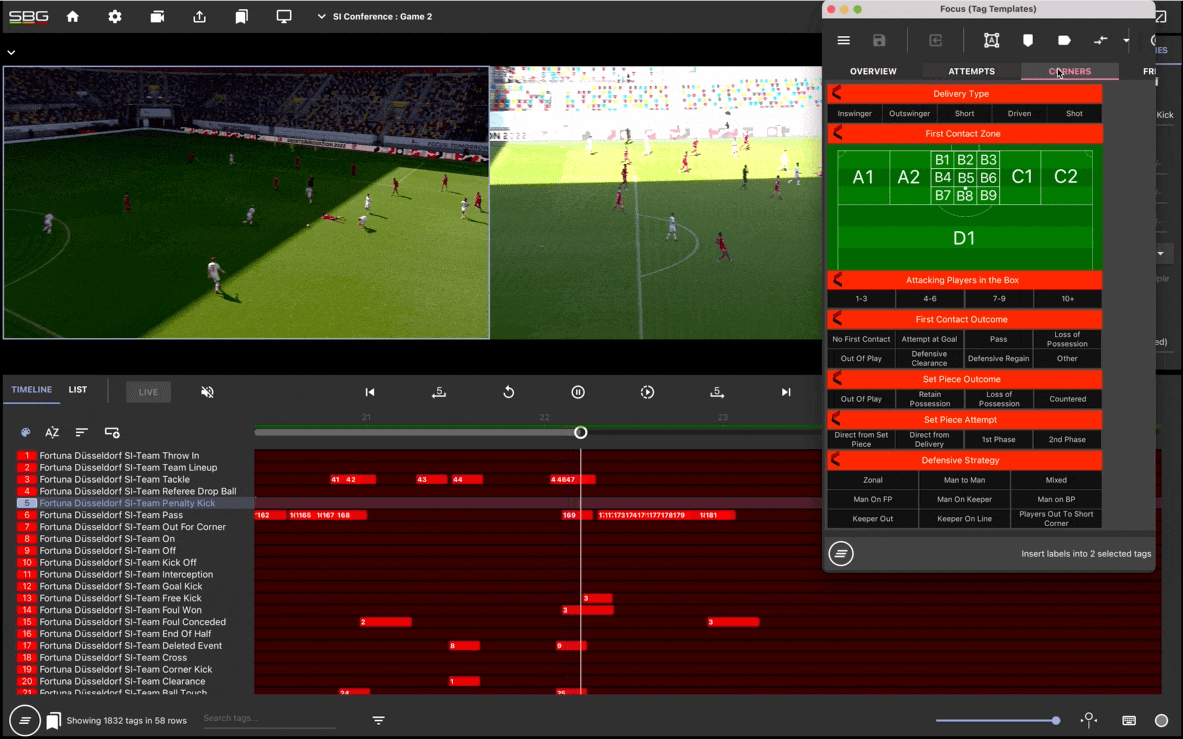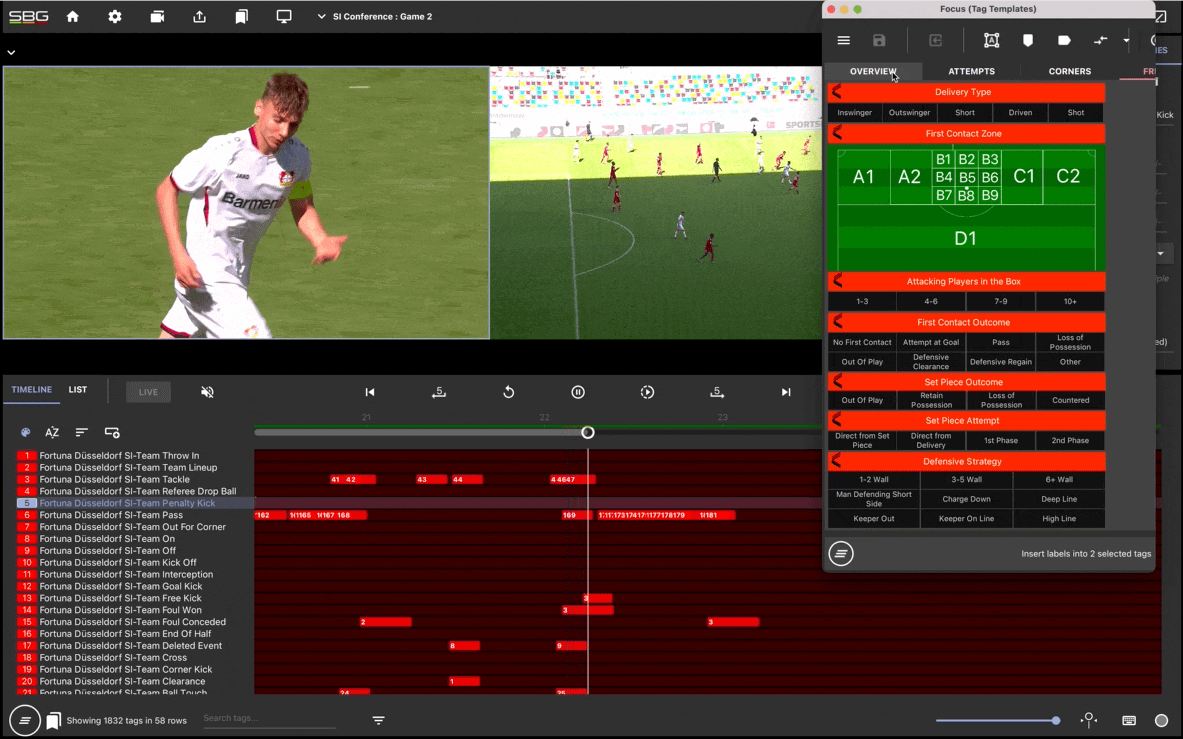
And, because of the clear unmet need and the relatively attractive risk balance, the bulk of new cancer drugs are first approved for patients who have already been through several rounds of treatment (called a “later line” treatment). It feels much safer to test an investigational drug in a dying patient with no other options than in a newly diagnosed patient who is giving up their chance to take the already approved “first line” therapy.
A footnote on AI:
If you’ll permit me to get nerdy for a second, consider how reinforcement learning works. A model generates some output (in our setting, perhaps a scientific hypothesis), that output is tested (e.g. an experiment is run), and if the model’s output was good, it receives a reward, if not, it’s punished. A variation of this process (“reinforcement learning with human feedback”) is what unlocked the performance in AI that led to ChatGPT: large models were trained on any text they could get their hands on, but then they were refined to produce output we liked by getting a bunch of 👍/ 👎from human reviewers. But RL is impractical at best, and impossible at worst, to implement in the sciences.
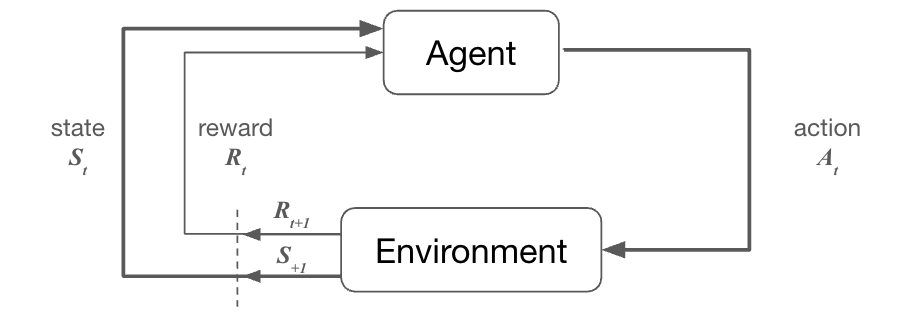
A traditional RL loop: an agent (model) observes the current state of the world (St) and decides on an action to take (At). That action interacts with the environment and produces an updated state (St+1) and receives feedback (positive or negative, Rt) about the quality of that action.
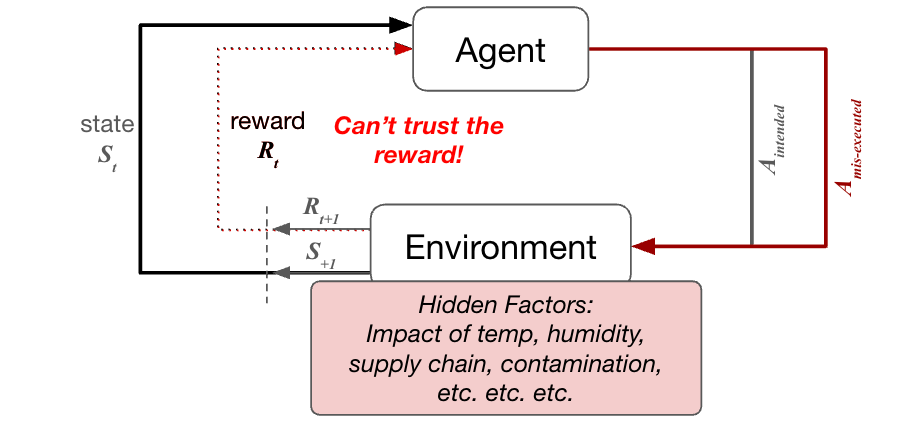
Now, let’s apply that to science… The Agent may come up with a hypothesis and an experiment in which to validate that hypothesis. Now, that action needs to be executed in the physical world. And this is where things go haywire… let’s say the experiment failed… In theory, the model should be punished for coming up with a bad hypothesis. But do we know the experiment failed because it was a bad idea? Or could it have just been mis-executed by a frazzled scientist trying to get out of the lab early (or a poorly-programmed robot)? Or… could it have been a little cold in the lab today? Or… maybe a reagent had expired? Or… maybe a piece of equipment was miscalibrated. You get the point. If we don’t fully understand the environment and can’t fully observe the action that was taken, we don’t really understand the signal we’re generating and can’t generate a valid reward function for the model. The model learns from the noise, rather than the signal.
We are already seeing this play out. Large-scale biology datasets have repeatedly discovered that models learn batch-to-batch and site-to-site variability as readily as underlying biology. TCGA famously clustered tumors by sequencing center rather than subtype, forcing the field to develop batch-correction methods. UK Biobank imaging models learned scanner identity. Pathology models learned stain and lab artifacts instead of disease. In each case, we see that without clarity and observability into the differences between the processes, it becomes difficult to train the AI to generalize around the desired signal.
F1 even invented the world’s fastest filming drone to keep up with the cars!
While we’re in the section about AI, can I just say how mad I am that AI has stolen the em-dash? All em-dashes in this piece are my own! #takebacktheemdash
As far as I can tell, none of my Waymo AI models have been watching YouTube/TikTok or talking on the phone while driving, none have been pulled over by cops, none have hotboxed their car (or allowed their passengers to), none have taken me on white-knuckled races down the highway. It’s not perfect, but under most conditions, it’s a hell of a lot better than the alternative.
This story earns some special recognition in Acquired’s coverage of Google. In 2004, DARPA offered $1 million to any team that could design an autonomous vehicle that could complete a 142-mile course through the Mojave Desert. One hundred teams showed up. None finished. The best-performing vehicle made it just 7.4 miles before getting stuck. The next year, the learnings were unmistakable. Of the 23 finalist teams, 22 passed the point where the 2004 leader had failed and 5 vehicles completed the entire course. In one year, the frontier of what was possible moved more than a hundred miles, not because anyone had a sudden theoretical breakthrough, but because the community could see what was happening and iterate together. Observability didn’t just help individual teams improve. It accelerated the entire field.
I, on the other hand, am allowed to keep driving with no marks against me on my license / car insurance despite being in two car accidents, at least one of which was most definitely my fault. We hold robots to a higher standard than we hold ourselves.
Very meta.
Recently, a plate heater got discalibrated before an important experiment/pilot and we were stuck in trouble shooting mode for a week before we realized the issue.
Hey — I came across your writing and really liked how you think.
I’m exploring something similar from a different angle — writing about human behavior through a system design lens (like debugging internal patterns).
Just started publishing on Substack. If you ever get a moment to read, I’d genuinely value your perspective.
Also happy to support your work — feels like there’s an interesting overlap here.